CLIP Search#
CLIP Search is a search paradigm that uses the CLIP model to encode the text and image documents into a common vector space. The search results are then retrieved by computing the cosine similarity between the query and the indexed documents. Technically, CLIP search can be designed as a two-stage process: encoding and indexing.
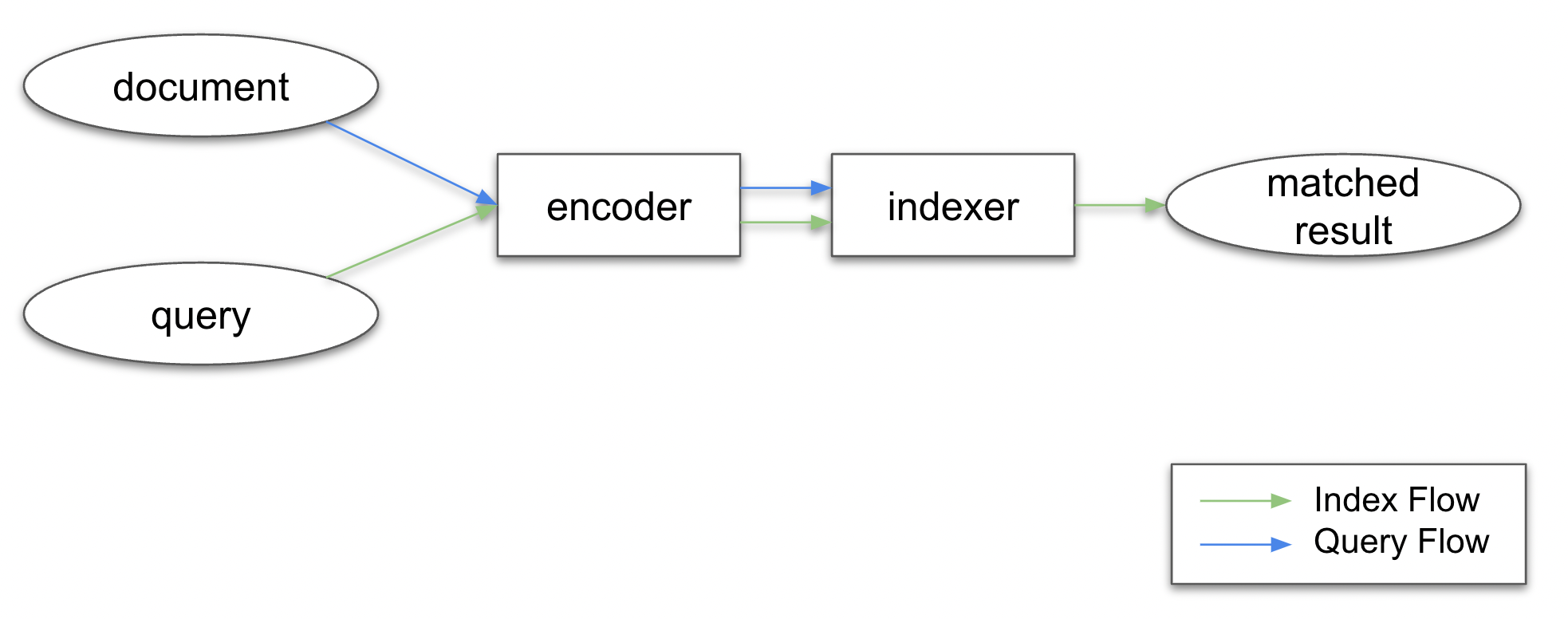
At the encoding stage, the text and image documents can be encoded into a common vector space by the CLIP model. It enables us to achieve cross-modal search, i.e., we can search for images given a text query, or search for text given an image query. At the indexing stage, we use the encoded vectors to build an index, which is a data structure that can be used to efficiently retrieve the most relevant documents. Specifically, we use the Annlite indexer executor to build the index.
This chapter will walk you through the process of building a CLIP search system.
Tip
You will need to install server first in Python 3.7+: pip install clip-server[search]>=0.7.0.
Start the server#
To start the server, you can use the following command:
python -m clip_server search_flow.yml
The search_flow.yml is the yaml configuration file for the search flow. It defines a Jina Flow to implement the CLIP search system.
Below is an example of the Flow YAML file, we can put it into two subsections as below:
jtype: Flow
version: '1'
with:
port: 61000
executors:
- name: encoder
uses:
jtype: CLIPEncoder
metas:
py_modules:
- clip_server.executors.clip_torch
- name: indexer
uses:
jtype: AnnLiteIndexer
with:
n_dim: 512
metas:
py_modules:
- annlite.executor
workspace: './workspace'
jtype: Flow
version: '1'
with:
port: 61000
executors:
- name: encoder
uses:
jtype: CLIPEncoder
with:
metas:
py_modules:
- clip_server.executors.clip_torch
- name: indexer
uses:
jtype: AnnLiteIndexer
with:
n_dim: 512
limit: 10
metas:
py_modules:
- annlite.executor
workspace: './workspace'
The first part defines the CLIP model config, which is explained here. And the second part defines the Annlite indexer config, you can set the following parameters:
Parameter |
Description |
|---|---|
|
The dimension of the vector space. It should be the same as the dimension of the CLIP model. |
|
The number of the most relevant documents to be retrieved. The default value is 10. |
And the workspace parameter is the path to the workspace directory, which is used to store the index files.
Index and search documents#
Tip
You will need to install client first in Python 3.7+: pip install clip-client>=0.7.0.
Index Documents#
To index image or text documents in the CLIP search server, you can use the client function index():
from clip_client import Client
from docarray import Document
client = Client('grpc://0.0.0.0:61000')
client.index(
[
Document(text='she smiled, with pain'),
Document(uri='apple.png'),
Document(uri='https://clip-as-service.jina.ai/_static/favicon.png'),
]
)
You don’t need to call client.encode() explicitly since client.index() will handle this for you.
Search Documents#
Then, you can use the client function search() to search for similar documents:
result = client.search(['smile'], limit=2)
print(result['@m', ['text', 'scores__cosine']])
The results will look like this, the most relevant doc is “she smiled, with pain” with the cosine distance of 0.096. And the apple image has the cosine distance of 0.799.
[['she smiled, with pain', ''], [{'value': 0.09604918956756592}, {'value': 0.7994111776351929}]]
You can set the limit parameter (default is 10) to control the number of the most similar documents to be retrieved.
Memory Estimation#
Here, we will show how to estimate the memory usage of AnnLite indexer.
This is useful for determining the amount of memory required for indexing and querying.
In AnnLite, the memory usage is determined by the following two components:
HNSWindexer: N * 1.1 * (4 bytes *dimension+ 8 bytes *max_connection), where N is the number of embedding vectors,dimensionis the dimension of the embedding vectors, andmax_connectionis the maximum number of connections in the graph.cell_table: it’s almost linear to the number of columns and number of data. If the default setting is used (no columns used for filtering), the memory usage ofcell_tableis 0.12GB per million data. Columns used for filtering are stored in string type so the memory usage is depended on the length of the string.
Support large-scale dataset#
When we want to index a large number of documents, for example, 100 million data or even 1 billion data, it’s not possible to implement index operations on a single machine. Sharding, a type of partitioning that separates a large dataset into smaller, faster, more easily managed parts, is needed in this case.
You need to specify the shards and polling in the YAML config:
jtype: Flow
version: '1'
with:
port: 61000
executors:
- name: encoder
uses:
jtype: CLIPEncoder
metas:
py_modules:
- clip_server.executors.clip_torch
- name: indexer
uses:
jtype: AnnLiteIndexer
with:
n_dim: 512
metas:
py_modules:
- annlite.executor
workspace: './workspace'
shards: 5
polling: {'/index': 'ANY', '/search': 'ALL', '/update': 'ALL',
'/delete': 'ALL', '/status': 'ALL'}
Parameter |
Description |
|---|---|
|
Number of shardings. |
|
Polling strategies for different endpoints. |
Then you can perform exactly the same operations as we do on a single machine.(/encode, /index and /search)
Why different polling strategies are needed for different endpoints?
Differences between ANY and ALL:
ANY: requests are sent to one of the executors.ALL: requests are sent to all executors.
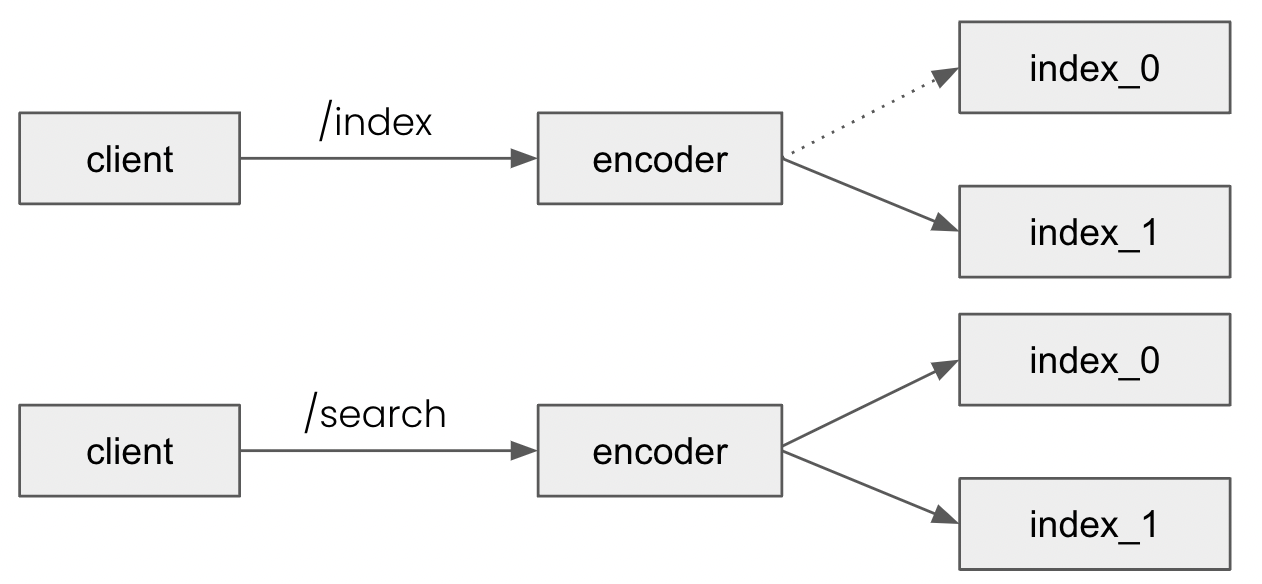
Since one data point only needs to be indexed once, there will only be one indexer executor that will handle this data point. Thus, ANY is used for /index. On the contrary, we use ALL in for /search since we don’t know which executor stores the perfectly matched result, so the search request should be handled by all indexer executors. (The same reason for using ALL in /update, /delete, /status)
Warning
Increasing the number of shardings will definitely alleviate the memory issue, but it will increase the latency since there will be more network connections between different shards.
